CORAL: When AI Agents Stop Following Scripts and Start Doing Science
A multi-agent framework where LLMs autonomously explore, reflect, and collaborate — achieving 3-10x improvement rates over rigid evolutionary search.
There’s a pattern in how we use large language models for discovery that, once you see it, is hard to unsee. We take a powerful reasoning engine — something that can hold an entire research problem in context — and we lobotomize it into a one-shot function call. Generate a candidate solution, evaluate it, mutate, repeat. The LLM becomes a glorified random number generator with good priors, stripped of the very capabilities that make it interesting: the ability to reflect, to remember, to change strategy when something isn’t working.
CORAL (Collaborative Open-ended Research Agent Library) is a framework from a large cross-institutional team1 that takes the opposite approach. Instead of forcing LLMs into the straitjacket of evolutionary operators, CORAL lets agents run autonomously for hours or days, exploring solution spaces the way a researcher actually would — trying things, taking notes, reading what colleagues found, and pivoting when they hit dead ends.
The results are striking: state-of-the-art on 10 benchmark tasks, with improvement rates 3–10× higher than existing methods. On Anthropic’s kernel optimization benchmark, four CORAL agents collaboratively improved a solution from 1363 to 1103 cycles — a level of sustained, autonomous improvement that prior frameworks simply couldn’t achieve.
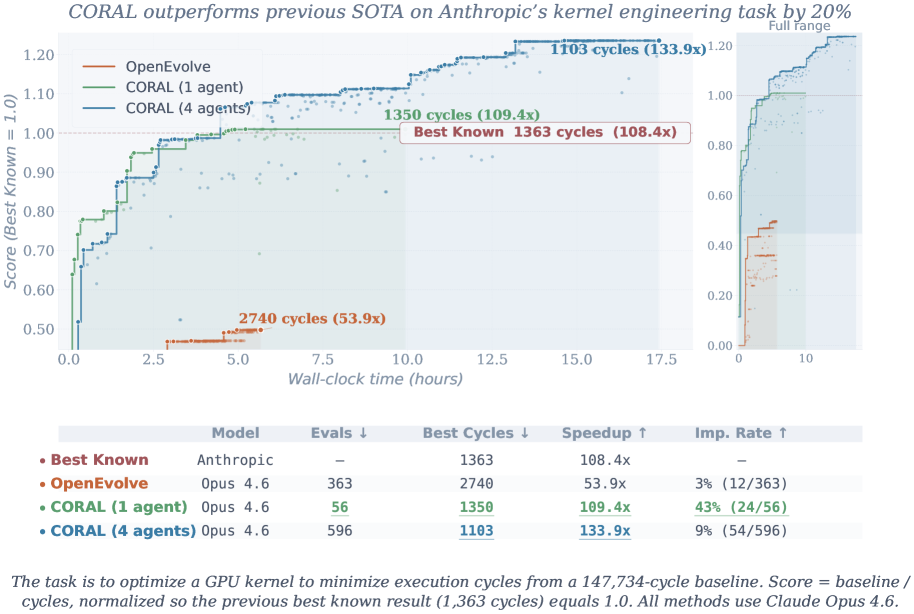
Figure 1: Three paradigms for LLM-based discovery — from rigid evolutionary search to CORAL’s autonomous agent approach.
The Problem With Evolutionary LLM Search
The dominant paradigm for using LLMs in automated discovery follows what the CORAL authors call the “LLM-based evolutionary search” pattern. Systems like FunSearch and EvoTorch treat the language model as a mutation operator within a larger evolutionary loop.2 The outer program maintains a population of solutions, selects parents, asks the LLM to produce offspring, evaluates fitness, and iterates.
This works — to a point. But it throws away most of what makes LLMs powerful. The model never sees the trajectory of its own attempts. It can’t reason about why a particular direction failed. It can’t decide to abandon one approach entirely and try something qualitatively different. Each generation is essentially a fresh start, with the LLM receiving only the current best solutions as context.
The second paradigm — what the authors term “LLM-based agentic search” — gives the model more autonomy within a single session. Systems like OpenHands let an agent interact with tools, read files, run code, and iterate on its own outputs.3 This is better, but still limited: the agent works alone, sessions are relatively short, and there’s no mechanism for knowledge to accumulate across runs.
CORAL represents a third paradigm: multi-agent autonomous research. Multiple agents run concurrently, each with full autonomy over their exploration strategy, sharing discoveries through a persistent knowledge base. The agents don’t just generate solutions — they conduct research.
How CORAL Actually Works
The framework is built around six interconnected modules, each addressing a specific limitation of prior approaches.

Figure 4: Architecture of CORAL showing its six core modules working in concert.
The Research Agent is the core unit. Each agent is an LLM (typically Claude or GPT-4) equipped with code execution tools, file I/O, and access to the shared knowledge base. Crucially, agents are given open-ended instructions — not “mutate this function” but “improve the solution for this problem, using whatever approach you think best.” The agent decides its own exploration strategy, manages its own workflow, and determines when to pivot or dig deeper.
Asynchronous Multi-Agent Execution allows multiple agents to work simultaneously on the same problem without blocking each other. This isn’t just parallelism for throughput — it’s parallelism for diversity. Different agents naturally explore different regions of the solution space, and the asynchronous design means a slow-but-promising exploration in one agent doesn’t bottleneck the others.4
The Shared Knowledge Base is perhaps the most critical innovation. Every agent can read from and write to a persistent repository of findings — successful approaches, failed experiments, useful intermediate results, and strategic observations. This transforms the agents from isolated researchers into a lab group. When Agent 3 discovers that loop unrolling helps on a particular kernel, Agent 1 can read that finding and combine it with its own discovery about memory alignment.5
Heartbeat-Based Intervention solves the long-running agent problem. Autonomous agents can get stuck — in infinite loops, unproductive rabbit holes, or simply running out their context window. CORAL implements a heartbeat mechanism where agents periodically report status, and an external monitor can intervene: injecting new information, suggesting strategy changes, or gracefully terminating unproductive runs.6
Evaluation Separation keeps the fitness function honest. Solution evaluation happens in isolated processes, separate from the agent’s own execution environment. This prevents agents from accidentally (or adversarially) gaming their own scores.
Resource Management handles the practical realities of running multiple LLM agents for extended periods: token budgets, compute allocation, workspace isolation, and graceful degradation when resources run low.
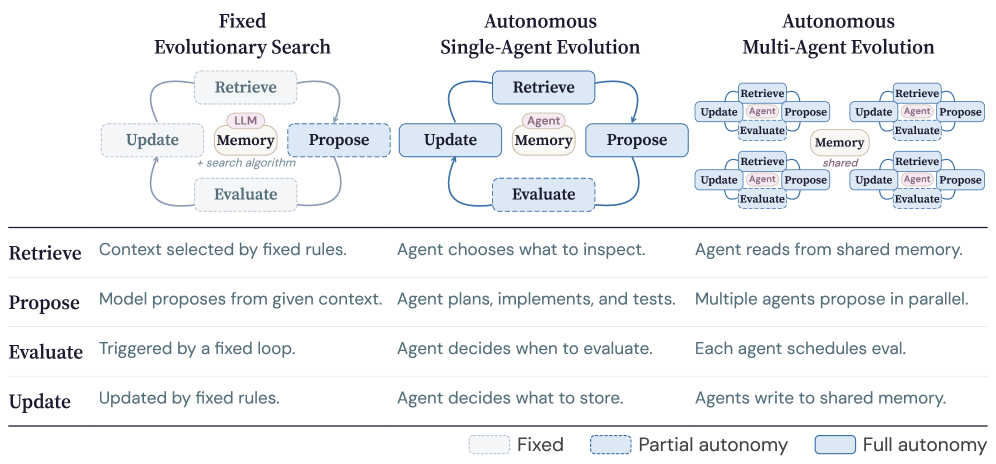
Figure 2: Overview of the CORAL framework — agents explore autonomously while sharing knowledge through persistent memory.
The Numbers
CORAL was evaluated across 10 tasks spanning combinatorial optimization, code optimization, and mathematical discovery. The headline numbers are genuinely impressive.
On polyomino packing7 — a notoriously hard combinatorial problem — CORAL achieved 89.4% coverage compared to 56% for the best baseline. That’s not an incremental improvement; it’s a qualitative jump that suggests the agents found fundamentally different packing strategies rather than minor optimizations of existing ones.
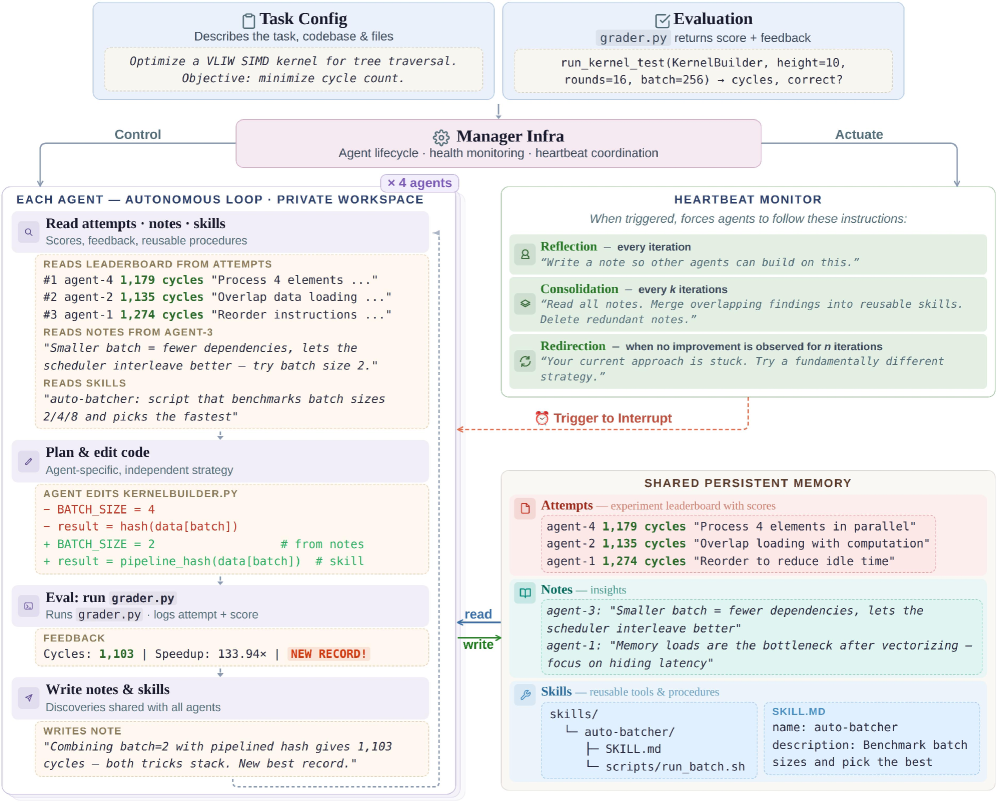
Figure 3: Polyominoes packing results — CORAL achieves 89.4% coverage versus 56% for baseline methods.
On Anthropic’s kernel optimization task — where the goal is to minimize execution cycles for GPU compute kernels — four CORAL agents working together improved a solution from 1363 to 1103 cycles. This task is particularly interesting because it requires deep systems-level reasoning: understanding memory hierarchies, instruction-level parallelism, and hardware-specific optimization opportunities. The fact that LLM agents can make meaningful progress here, autonomously, over extended runs, is a strong signal about the viability of AI-driven systems optimization.
Across all tasks, CORAL achieved 3–10× higher improvement rates compared to both evolutionary and single-agent baselines. The improvement is most dramatic on tasks that reward sustained, strategic exploration — exactly the regime where CORAL’s design advantages should matter most.
Figure 5: Additional benchmark results across CORAL’s evaluation suite.
Why Knowledge Reuse Changes Everything
The most underappreciated aspect of CORAL is how knowledge reuse and multi-agent communication interact to produce emergent research behaviors.
In traditional evolutionary search, knowledge is implicit — encoded in the population of solutions. If a useful building block emerges, it survives only if it’s attached to a high-fitness individual. There’s no way to say “this technique didn’t improve the overall score, but it solved a subproblem that might be useful later.”
CORAL’s shared knowledge base changes this dynamic fundamentally. Agents write structured observations — not just code, but explanations of what they tried, why they think it worked or didn’t, and what they’d suggest trying next. This is closer to how actual research labs function: through lab notebooks, group meetings, and shared institutional knowledge.8
The paper reports several instances of emergent collaboration patterns. In one kernel optimization run, an agent spent significant compute exploring vectorization strategies that didn’t directly improve the score. But its notes about the memory access patterns it discovered were picked up by another agent, which combined that insight with its own work on cache optimization to produce a breakthrough solution. Neither agent alone would have found it. The combination of knowledge from different exploration trajectories created something new.
This is, in essence, the recombination that evolutionary algorithms try to achieve — but at the level of ideas rather than code fragments. When you recombine two code strings, you usually get garbage. When you recombine two insights, expressed in natural language and interpreted by a reasoning engine, you often get something useful.9
The knowledge base also enables a form of negative transfer prevention. Agents can read about failed approaches and avoid repeating them. In long optimization runs, this matters enormously — a naive agent might spend hours rediscovering that a particular approach is a dead end, while a CORAL agent can read a colleague’s note and skip straight to more promising territory.
Safety and Containment
Running autonomous agents for hours or days, with code execution capabilities, raises obvious safety concerns. CORAL addresses these with a layered approach that’s more thoughtful than most frameworks I’ve seen.
Each agent operates in an isolated workspace — a sandboxed environment where it can read, write, and execute code without affecting other agents or the host system. The evaluation pipeline is strictly separated from the agent’s execution environment, preventing agents from manipulating their own fitness scores.10 Resource management enforces token budgets and compute limits, ensuring that a runaway agent can’t consume unbounded resources.
The heartbeat mechanism serves double duty here: it’s both an efficiency tool (catching stuck agents) and a safety mechanism (providing regular checkpoints where human operators can inspect agent behavior and intervene if necessary).
This isn’t a solved problem — the authors are appropriately cautious about the risks of increasingly autonomous AI systems — but it’s a responsible engineering approach that takes containment seriously without using it as an excuse to cripple the agents’ capabilities.
What This Means for the Field
CORAL sits at an interesting inflection point in AI research. We’ve been gradually expanding the autonomy we give to language models — from single-turn completions, to multi-turn conversations, to tool-using agents, to long-running autonomous researchers. Each step has been met with skepticism (“LLMs can’t really do X”) followed by demonstrations that, with the right scaffolding, they can.
The connection to work on self-improving agents is direct. Where EvoSkills showed that agents can write their own skill libraries — essentially expanding their own capabilities — CORAL shows that agents can conduct open-ended research autonomously. These are complementary capabilities. An agent that can both expand its skill set and conduct sustained research is starting to look like something qualitatively different from a chatbot.
The 3–10× improvement over evolutionary baselines is important not just as a number but as evidence for a thesis: that LLMs are underutilized when we treat them as components in traditional optimization loops. The models already have the capacity for reflection, strategy, and knowledge accumulation. We just need frameworks that let them use those capacities.11
Whether CORAL specifically becomes the standard framework matters less than the paradigm shift it represents. The era of “LLM as mutation operator” is ending. The era of “LLM as autonomous researcher” is beginning. The question is no longer whether AI agents can do useful discovery work, but how we structure, coordinate, and contain them as they do.
Paper: “CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery” — Qu, Zheng, Zhou, Yan, Tang, Ong, Hong, Zhou, Jiang, Kong, Zhu, Jiang, Li, Wu, Low, Zhao, Liang. arXiv:2604.01658. April 2026.