Agents Are Now Writing Their Own Instruction Manuals
A new paper shows that AI agents can create their own skill packages through iterative self-verification, outperforming human-authored ones by 17 points and transferring across models with massive gains.
A new paper shows that AI agents can create their own skill packages, and the results outperform human-authored ones by a wide margin.
If you’ve spent any time building with AI agents in the last year, you’ve probably hit the same wall everyone else has: getting them to reliably do complex, multi-step tasks is hard. Not because the models are dumb — they’re shockingly capable — but because the gap between “can answer a question” and “can execute a 15-step workflow across multiple files, tools, and recovery scenarios” is enormous.1
The industry’s answer to this has been skills. Anthropic formalized the concept: instead of giving an agent a single tool (a function it can call) or a single prompt (text instructions), you give it a skill — a structured package containing workflow instructions, executable scripts, reference documents, and domain knowledge, all bundled together. Think of it as the difference between handing someone a hammer versus giving them a carpentry manual.
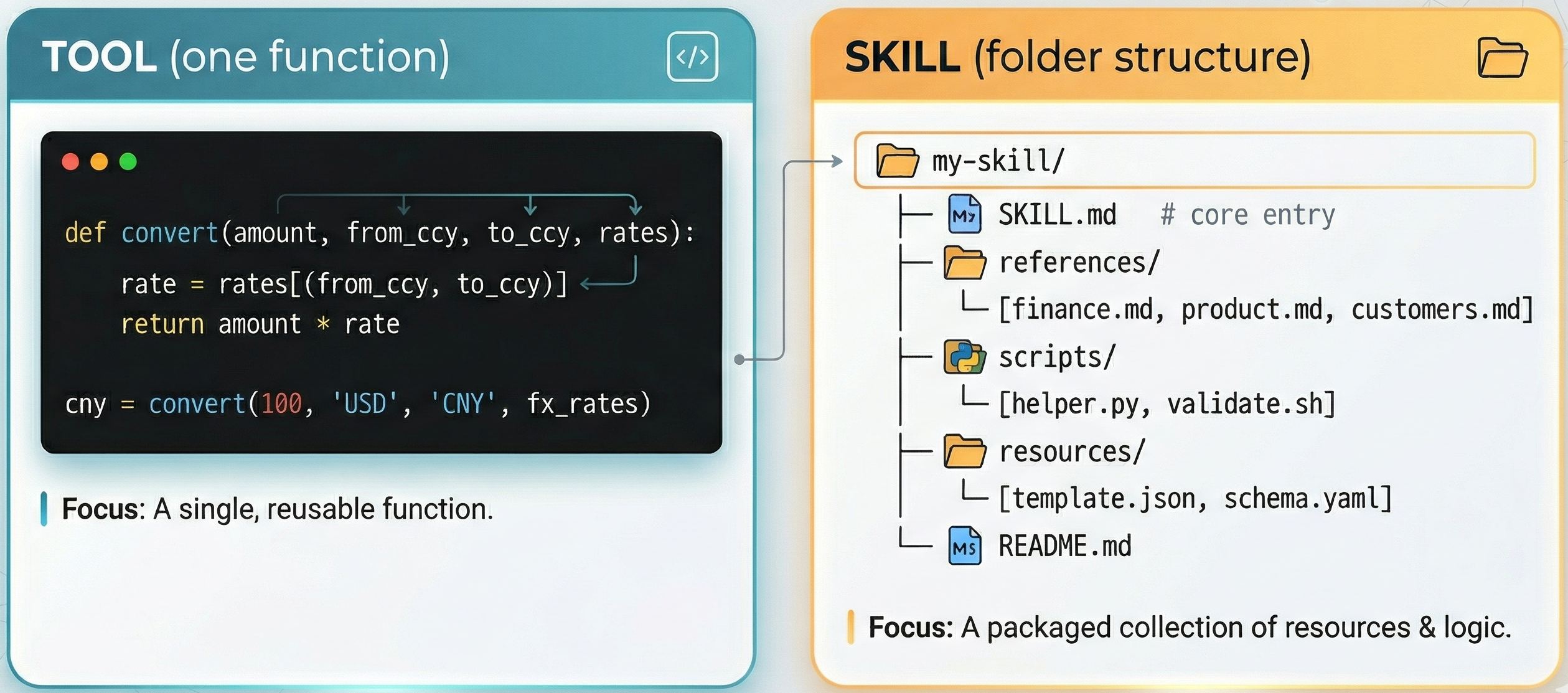
The difference between a tool and a skill. A tool is a single reusable function (e.g., currency conversion). A skill is a complete multi-file package containing instructions (SKILL.md), reference documents, scripts, resources, and a README — everything an agent needs to execute a complex workflow. Source: Zhang et al., 2026.
The problem? Writing good skills is incredibly labor-intensive. It’s basically technical writing meets systems engineering. You need to understand the task domain, the agent’s capabilities and limitations, the tool interfaces, the failure modes, and how to structure instructions in a way that a language model will actually follow. Most people who try to write skills for agents find that the results are inconsistent — some tasks benefit enormously, others actually get worse with skill integration.
A paper dropped this week that asks a question that should have been obvious in retrospect: what if we let the agents write their own skills?
The Human-Machine Cognitive Gap
The paper is called EvoSkills, from a collaboration across UIC, MBZUAI, McGill, Columbia, Zhejiang, and UBC.2 The core insight is deceptively simple but has big implications.
When humans write skills for AI agents, there’s a fundamental mismatch. We write instructions the way we think about problems — using abstractions, shortcuts, and assumptions that make sense to human experts. But agents don’t process information the way we do. They have different strengths (pattern matching across massive context), different weaknesses (maintaining state across long workflows), and different failure modes (they don’t “forget” — they lose context).
The SkillsBench evaluation (87 tasks across 11 professional domains)3 makes this painfully clear.4 Human-curated skills help substantially in some domains but actually degrade performance in others, like Natural Science. The researchers call this human-machine cognitive misalignment: the workflows that make sense to human experts don’t match how LLM agents actually reason, act, and recover from errors.
So the question becomes: what if the agent could write instructions that match its own cognitive patterns?
The Architecture: Two Agents, One Loop
The EvoSkills framework has two main components, and the way they interact is the clever part.
The Skill Generator is an LLM agent that creates skill packages. Not one-shot — iteratively. It starts with a rough draft, runs it, gets feedback, and revises. It maintains a persistent conversation context that accumulates lessons from each attempt.
The Surrogate Verifier is a separate LLM session that evaluates the skill’s output. Crucially, it’s informationally isolated — it can’t see the Skill Generator’s code, reasoning, or internal state.5 It only sees the task instructions and the output files. This prevents the verifier from inheriting the generator’s blind spots or biases.
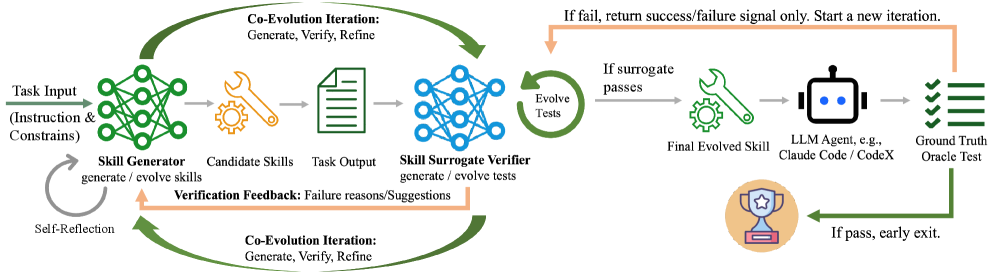
The EvoSkills co-evolutionary framework. The Skill Generator creates candidate skills, which an LLM Agent executes. The Surrogate Verifier independently generates tests and evaluates output. A Ground Truth Oracle provides only binary pass/fail signals. When the surrogate passes but the oracle fails, the verifier escalates by writing harder tests. Structured failure feedback loops back to drive iterative refinement. Source: Zhang et al., 2026.
The two co-evolve through a loop:6
The Generator creates a skill package and executes it
The Verifier independently generates test assertions and evaluates the output
If tests fail, the Verifier produces a structured diagnostic (what failed, root cause analysis, suggested fixes)
The Generator uses that feedback to refine the skill
If the Verifier’s tests pass but the ground-truth oracle test fails, the Verifier escalates — it writes harder, more comprehensive tests
That last step is key. The ground-truth oracle only returns a binary pass/fail signal.7 No details. No test content. This forces the Verifier to independently figure out what it’s missing, which prevents both components from overfitting to the hidden tests. It’s a genuinely elegant solution to the feedback problem in self-improvement systems.8
The whole thing converges within about 5 iterations.9 The skill quality improvement is roughly monotonic — each round gets better — and the framework hits its ceiling relatively quickly.
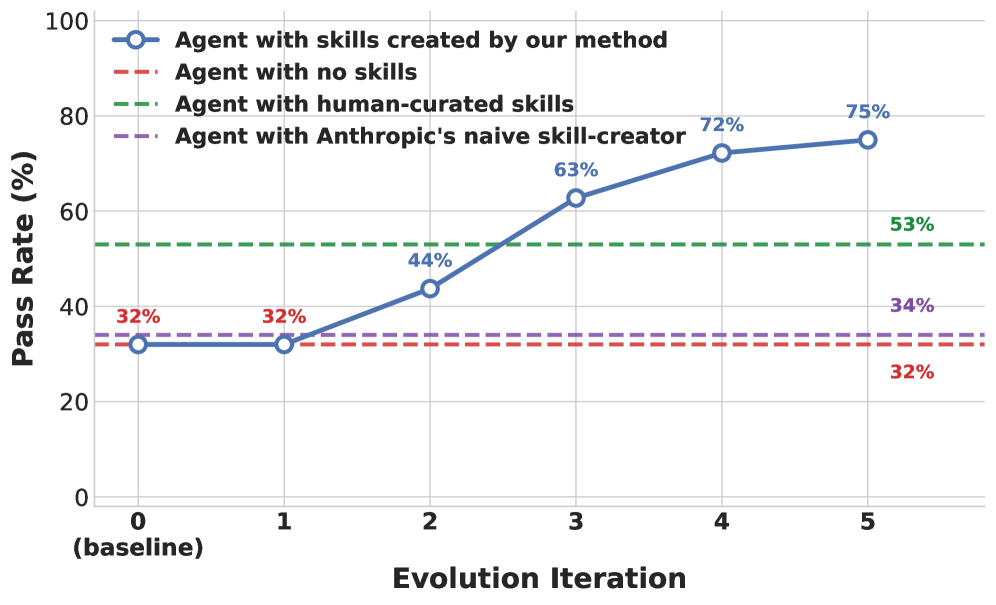
Skill quality improvement across 5 evolution rounds. EvoSkills surpasses human-curated skill performance within just 5 iterations, while the no-skill baseline and naive skill-creator remain flat. Source: Zhang et al., 2026.
The Results: Agents > Humans
Let’s talk numbers, because they’re striking.
On SkillsBench (87 tasks, 11 domains), using Claude Opus 4.6 with Claude Code as the execution agent:10
Method |
Pass Rate |
|---|---|
No skills (baseline) |
30.6% |
Self-generated skills (one-shot) |
32.0% |
CoT-guided self-generation |
30.7% |
Anthropic’s Skill-Creator |
34.1% |
Human-curated skills |
53.5% |
EvoSkills |
71.1% |
Read that again. The agent-evolved skills beat human-curated skills by 17.6 percentage points. And they beat the no-skill baseline by over 40 points.11
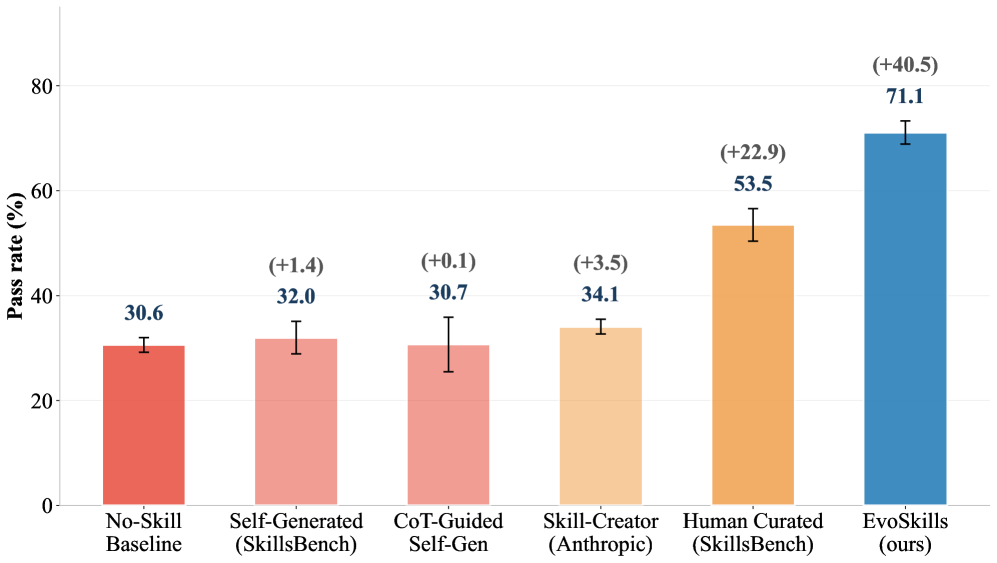
Pass rate comparison across methods on SkillsBench. EvoSkills (71.1%) dramatically outperforms all alternatives including human-curated skills (53.5%). Note how one-shot self-generation and CoT-guided approaches barely improve over the no-skill baseline. Source: Zhang et al., 2026.
But look at the other self-generation methods. One-shot skill generation barely moves the needle. Adding chain-of-thought doesn’t help. Even Anthropic’s own skill-creator tool only gets to 34.1%. The gains aren’t coming from the act of generating a skill — they’re coming from the iterative verification loop. Without the Surrogate Verifier, EvoSkills drops from 71.1% to 41.1%. The co-evolution is doing the heavy lifting.12
This tells us something important: the bottleneck isn’t the model’s ability to write instructions. It’s the model’s ability to validate and refine those instructions against actual execution results.
Deep Dive: Why Naive Self-Generation Fails
The gap between naive self-generation (32.0%) and EvoSkills (71.1%) is the most important number in this paper. It tells us that the act of writing a skill is not the hard part — the act of refining it is.
When a model generates a skill in one shot, it’s essentially doing speculative planning: “Here’s what I think will work for this task.” The problem is that speculative plans fail in predictable ways:
Missing edge cases. The model doesn’t know that the input CSV has mixed date formats until it actually tries to parse it.
Incorrect assumptions about tool behavior. The model assumes
pandas.read_csv()will handle encoding automatically. It won’t.Vague recovery instructions. “If an error occurs, try an alternative approach” is useless. “If
FileNotFoundErroris raised when accessingdata/input.xlsx, check for case-insensitive matches in the directory listing” is actionable.Wrong level of abstraction. Human-style instructions say “analyze the dataset.” Agent-effective instructions say “load the file, check dtypes, handle nulls in columns A-C by forward-filling, compute the requested metrics, validate output shape matches expected dimensions, write to CSV with UTF-8 encoding.”
Chain-of-thought doesn’t fix this because the reasoning is still speculative. The model thinks harder about what might work, but it’s still guessing. It hasn’t actually tried running anything.
The Surrogate Verifier changes the game because it introduces empirical feedback from execution. Round 1’s skill fails because it didn’t handle a specific edge case. The Verifier diagnoses this, the Generator fixes it. Round 2’s skill fails because the output format doesn’t match expectations. Fix, retry. By round 5, the skill has been pressure-tested against real execution and iteratively hardened against the actual failure modes — not hypothetical ones.
The 32% → 71% gap is the difference between planning and doing.
They Transfer Across Models
Here’s where it gets really interesting for anyone building production systems. The researchers took skills evolved by Claude Opus 4.6 and transferred them — unchanged — to six completely different models from five different companies:13
Model |
No Skill → With EvoSkills |
Improvement |
|---|---|---|
29.6% → 65.0% |
+35.4pp |
|
20.0% → 63.1% |
+43.1pp |
|
10.4% → 54.5% |
+44.1pp |
|
8.4% → 50.8% |
+42.4pp |
|
13.0% → 48.8% |
+35.8pp |
|
4.9% → 43.1% |
+38.2pp |
These are massive gains. Haiku goes from solving 10% of tasks to solving 55%. Mistral goes from under 5% to over 43%. And these are skills written by a completely different model.14
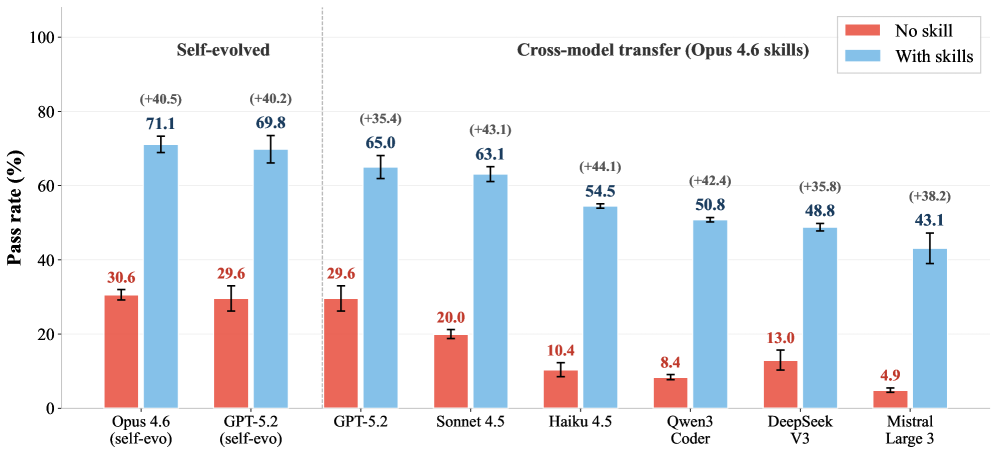
Cross-model skill transferability. Skills evolved by Claude Opus 4.6 produce massive performance gains when transferred to six other models across five providers — demonstrating that the skills encode reusable task structure, not model-specific tricks. Source: Zhang et al., 2026.
This tells us the skills aren’t encoding model-specific tricks or artifacts. They’re encoding reusable task structure — the actual workflow logic, error handling, and domain knowledge that any capable agent needs. The skill is genuinely capturing something about the task, not something about the model that wrote it.
What the Skills Actually Look Like
One thing worth dwelling on: these aren’t simple prompts or single files. Each EvoSkills package is a structured, multi-file bundle containing:15
SKILL.md: The main instruction document — workflow steps, decision trees, failure recovery procedures
Executable scripts: Python scripts, shell commands, validation tools
Reference materials: Domain-specific knowledge, API documentation, format specifications
Templates: Output templates, configuration files
The Skill Generator doesn’t just write instructions — it writes an entire operational package that the agent can reference during execution. And because the Generator has actually tried executing the task and received detailed failure diagnostics, the resulting packages include practical details that human authors miss: specific error handling for common failures, workarounds for tool limitations, and recovery strategies the agent learned through trial and error.
This is the cognitive alignment advantage. A human writing a skill for “analyze this financial dataset” thinks about the analytical methodology. The agent writing a skill for the same task also includes: “if pandas throws a dtype error on column X, try casting to float64 first” and “always verify the output CSV has the expected number of rows before declaring success.” These operational details are boring and unglamorous, but they’re exactly what separates a 30% pass rate from a 70% one.
Deep Dive: Anatomy of an Evolved Skill
Here’s a simplified example of what an EvoSkills package looks like after 5 rounds of evolution, based on patterns described in the paper. This is for a hypothetical “analyze sales data” task:
SKILL.md (main instruction document):
# Skill: Sales Data Analysis
## Pre-flight Checks
1. Verify input file exists at expected path. If not, search current directory for .csv/.xlsx files.
2. Check file encoding (try UTF-8, then Latin-1, then cp1252).
3. Load first 5 rows and verify expected columns exist (case-insensitive match).
## Workflow
1. Load full dataset with explicit dtype mapping: dates as str (parse later), amounts as float64.
2. Handle missing values: forward-fill for dates, 0 for amounts, "Unknown" for categories.
3. Parse dates using dateutil.parser with dayfirst=False. If >5% fail, try dayfirst=True.
4. Compute requested metrics (see task description for specifics).
5. Generate output CSV with columns in exact order specified by task.
## Validation Before Submission
- [ ] Output file exists and is non-empty
- [ ] Column names match expected (case-sensitive)
- [ ] Row count is within 10% of input row count (unless aggregation expected)
- [ ] No NaN values in output unless explicitly permitted
- [ ] File encoding is UTF-8
## Known Failure Modes
- pandas.read_csv silently drops rows with too many delimiters → use error_bad_lines=False and log count
- Large files (>100MB) may cause memory issues → use chunked reading with chunksize=50000
- Date columns with mixed formats → split and parse separately, then mergevalidate_output.py (self-validation script):
import pandas as pd
import sys
def validate(output_path, expected_columns):
df = pd.read_csv(output_path)
assert not df.empty, "Output file is empty"
for col in expected_columns:
assert col in df.columns, f"Missing column: {col}"
assert not df.isnull().all().any(), "Column entirely null"
print("Validation passed")
if __name__ == "__main__":
validate(sys.argv[1], sys.argv[2:])Notice what’s different from a human-authored skill: the pre-flight checks, the explicit encoding fallback chain, the validation checklist, and the “known failure modes” section. These all came from the agent actually failing on these issues during evolution rounds and having the Verifier diagnose the root cause. A human author might mention “handle missing values” — the evolved skill specifies exactly how, because it learned the hard way what happens when you don’t.
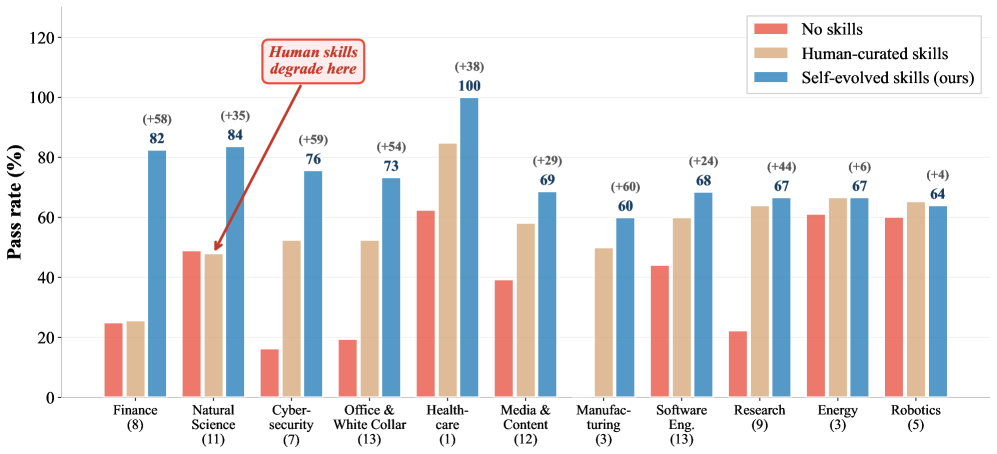
Per-domain pass rates across 11 professional domains. Three conditions compared: no skills (baseline), human-curated skills, and EvoSkills. Notably, human-curated skills actually degrade performance in Natural Science, while EvoSkills improves across nearly all domains. Source: Zhang et al., 2026.
The Takeaway: Self-Improvement Works (With Guardrails)
There’s a broader narrative here about self-improvement in AI systems, and EvoSkills contributes an important data point.
Naive self-improvement doesn’t work. Asking a model to generate skills in one shot is barely better than no skills at all. Asking it to think harder (CoT) doesn’t help either. The model needs:
Execution feedback: You have to actually run the skill and see what happens. Hypothetical reasoning about what might work isn’t enough.
Independent verification: Self-evaluation is compromised by the same blind spots that caused the errors. You need a separate evaluator that can’t see your reasoning.
Iterative refinement: Quality improves monotonically across rounds. The first draft is always rough. The fifth draft is usually good.
Escalating standards: When the surrogate tests pass but the oracle fails, the verifier has to independently figure out what it missed and write harder tests. This prevents convergence to easy-to-pass-but-wrong solutions.
If you’re building agent systems today, the practical implication is clear: invest in skill evolution pipelines, not just skill writing. A human-written skill that costs hours to create and gets 53% pass rate is less valuable than a machine-evolved skill that takes a few iterations and gets 71%. And the machine-evolved version transfers to other models for free.
The authors frame their core finding as: “Agents that evolve their own skills consistently outperform those guided by human-curated procedures.” Not because agents are smarter than humans, but because they’re writing instructions for themselves, in a format that matches their own reasoning and execution patterns. They know what they need in a way that human authors can only approximate.
There’s something philosophically interesting happening when an AI agent writes instructions for other AI agents that are better than what humans can write. It’s not AGI. It’s not even close. But it is a kind of cognitive self-awareness — the system understanding its own strengths and failure modes well enough to create operational documentation that accounts for them.
Paper: “EvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification” — Zhang, Fan, Zou, Chen, Wang, Zhou, Li, Huang, Yao, Zheng, Liu, Li, Yu. UIC / MBZUAI / McGill / Columbia / Zhejiang / UBC. arXiv:2604.01687. April 2026.