The End of Thinking Out Loud: AI’s Future Is in Latent Space
A 68-page survey from 35+ researchers argues that the next generation of AI won’t reason in words at all — and why that shift is already underway across reasoning, planning, memory, and embodiment.
- What Is “Latent Space” In This Context?
- Why Words Are a Bad Medium for Thinking
- The Evolution: From Proof-Of-Concept to Paradigm
- The Four Mechanisms
- The Seven Abilities
- Deep Dive: How COCONUT Works
- Deep Dive: The Interpretability-Capability Tradeoff
- The Elephant in the Room: Interpretability
- Why This Matters Now
- The Bottom Line
A massive 68-page survey from 35+ researchers argues that the next generation of AI won’t reason in words at all.
Here’s a weird thing about modern AI that most people don’t think about: when GPT or Claude or Gemini “thinks,” it does so by generating words. Every intermediate step of reasoning — every “let me consider,” every “first, I need to,” every step of a chain-of-thought — is a token.1 A discrete, human-readable word that gets produced, one at a time, sequentially, left to right.
This is profoundly unnatural for a neural network.
The internal representation of a transformer is a continuous, high-dimensional vector space.2 Rich, dense, expressive. It can encode subtle relationships, probabilistic distributions, spatial configurations, and conceptual structures that would take paragraphs to express in English. But every time we ask a model to reason, we force it to squeeze all of that richness through a tiny bottleneck: the vocabulary. 50,000 discrete tokens. One at a time. In order.
It’s like asking a symphony orchestra to communicate exclusively through Morse code.
A new survey — 68 pages, 35+ authors, over 300 references — just dropped from a massive collaboration spanning NUS, Fudan, Tsinghua, Zhejiang, and about fifteen other institutions.3 It makes a sweeping argument: the future of AI isn’t in better token-level generation. It’s in latent space.
And if they’re right, the entire paradigm we’ve been building on for the last three years is about to shift.

Figure 1: Overview of the latent space methods classified by Mechanisms (vertical) and Abilities (horizontal). A single method may span multiple categories. Source: Yu et al., 2026.
What Is “Latent Space” In This Context?
Let me be precise, because this term gets thrown around loosely. In the context of this survey, “latent space” doesn’t mean the latent spaces you know from VAEs or diffusion models (though those are related).4 It means the continuous activation space inside a language model — the hidden states, the representations that exist between input and output.
Right now, most models work like this:
Input tokens → Internal processing (latent) → Output tokens
The latent part in the middle is where the actual computation happens. But we treat it as a black box. The thing we care about — the thing we train on, evaluate, and build products around — is the output tokens.
The thesis of this survey is that we should stop treating the middle part as a black box and start treating it as the primary computational medium. Instead of forcing models to externalize every intermediate thought as a readable word, let them think in their native representation: continuous vectors.
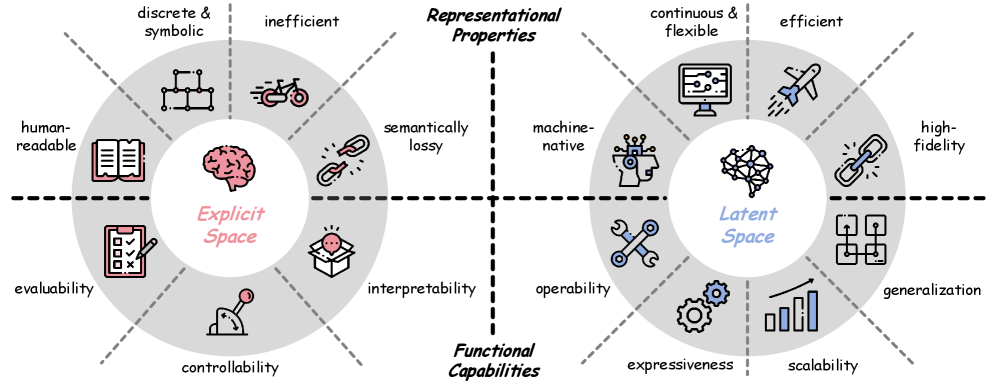
Figure 3: Comparison of the explicit space and latent space of language models, including their representational properties and functional capabilities. Source: Yu et al., 2026.
Why Words Are a Bad Medium for Thinking
The survey identifies four structural limitations of “explicit-space” (token-level) computation:
1. Linguistic redundancy. Natural language is full of filler. When a model generates a chain-of-thought like “Let me think about this step by step. First, I need to consider…” — most of those tokens carry zero informational content. They’re syntactic scaffolding. The model is burning compute on generating words that exist purely to satisfy the format of human language.
2. Discretization bottleneck. The model’s internal state is a 4096-dimensional (or higher) continuous vector. To produce the next reasoning step, it has to collapse that rich representation into a single token from a fixed vocabulary. Information is inevitably lost. It’s like compressing a high-resolution image into a single pixel and then trying to reconstruct from there.
3. Sequential inefficiency. Autoregressive generation is inherently serial.5 Each token depends on the previous one. You can’t parallelize it. If a reasoning chain is 500 tokens long, that’s 500 sequential forward passes. In latent space, a model could potentially process the equivalent information in a single forward pass through a deeper network, or through multiple parallel latent “thinking” steps.
4. Semantic loss. Some concepts — spatial relationships, probabilistic distributions, visual layouts, musical structures — are fundamentally difficult to express in discrete text. Forcing the model to verbalize these concepts doesn’t just slow things down; it actively degrades the quality of the reasoning.
The Evolution: From Proof-Of-Concept to Paradigm
The survey traces the development of latent-space methods through four phases, and the timeline tells a story about how quickly this field has moved.
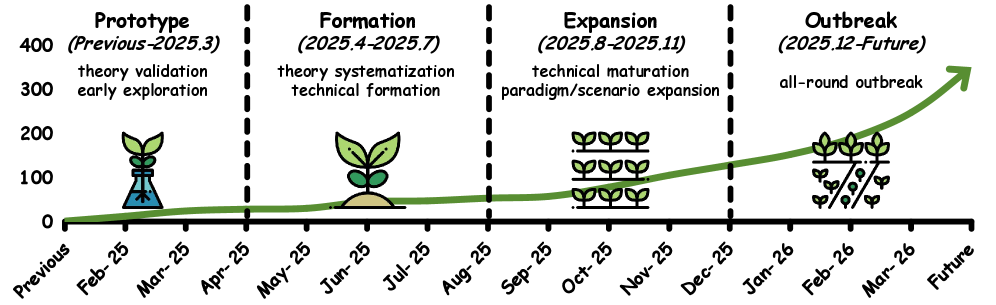
Figure 4: Timeline of representative works in the evolution of latent space research, organized into four developmental stages: Prototype, Formation, Expansion, and Outbreak. The horizontal axis denotes the month, and the vertical axis indicates the number of latent-level works. Source: Yu et al., 2026.
Prototype (pre-March 2025): The earliest work showed that language models already encode reasoning-relevant structure in their hidden states.6 You could find directions in activation space that correspond to truth, uncertainty, or logical entailment. A few papers experimented with “implicit chain-of-thought” — skipping the verbalized reasoning and instead training models to reach the right answer through internal computation alone.7
Formation (April–July 2025): This is when the field got serious. COCONUT (Chain of Continuous Thought) was a landmark paper that showed you could replace discrete chain-of-thought tokens with continuous latent vectors and maintain reasoning performance.8 The key insight was training models to “think” in a space that isn’t constrained by vocabulary or grammar. Other papers provided theoretical justifications for why latent reasoning could be more expressive than verbal reasoning.
Expansion (August–November 2025): Latent methods expanded beyond reasoning into planning, perception, memory, and multi-agent collaboration. People started using latent representations for multimodal fusion — processing images and text in a shared latent space instead of converting images to text descriptions. Embodied AI researchers began using latent action spaces for robot control. The paradigm was no longer just about “thinking without words” — it was becoming a general computational substrate.
Outbreak (December 2025–present): The current phase. The number of papers has exploded. The survey catalogs over 150 distinct methods across its taxonomy. Major labs are investing heavily. The question is no longer “does latent reasoning work?” but “how do we build entire systems around it?”
The Four Mechanisms
The survey organizes the technical landscape along four axes.
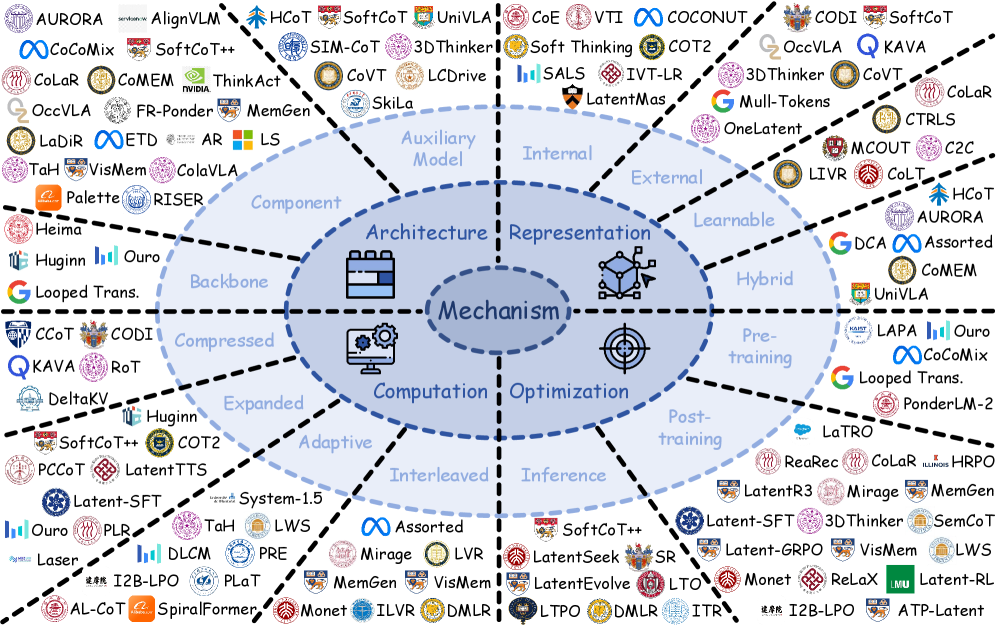
Figure 5: Representative works organized by latent space mechanisms: Architecture, Representation, Computation, and Optimization. Source: Yu et al., 2026.
Architecture
How do you structurally build latent computation into a model? Three approaches:
Backbone modifications: Changing the transformer architecture itself — adding recurrent connections, loop structures, or additional “thinking” layers that process latent states without generating tokens. Models like Huginn and LoopFormer fall here.9
Component additions: Adding specialized modules — latent thinking heads, pause tokens, perception tokens — that create dedicated latent processing pathways within an otherwise standard architecture.10
Auxiliary models: Using separate smaller models as latent “co-processors” that handle specific kinds of computation (planning, verification, memory retrieval) in latent space and feed results back to the main model.
Representation
What form do the latent representations take?
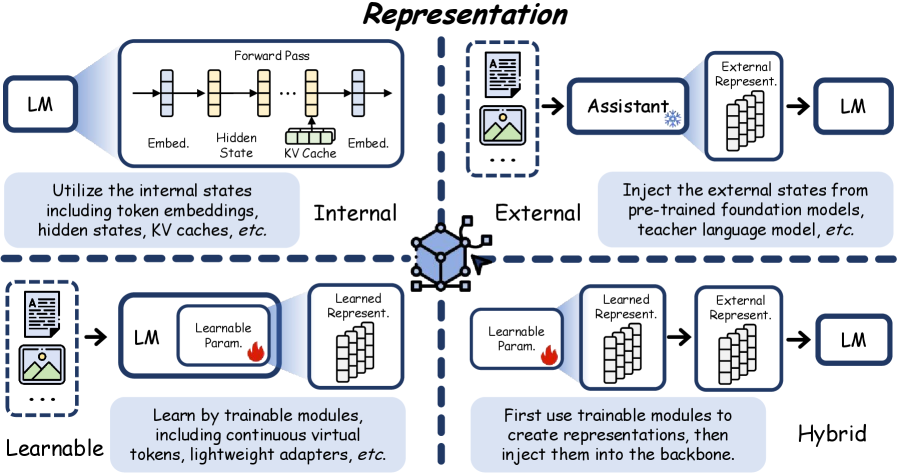
Figure 6: Schematic diagram of the Representation mechanism, including four sub-types: Internal, External, Learnable, and Hybrid. Source: Yu et al., 2026.
Internal: Using the model’s own hidden states as the latent representation.
External: Encoding information from outside the model (images, structured data, knowledge graphs) into latent vectors the model can process natively.
Learnable: Introducing new learnable parameters (soft tokens, continuous embeddings) that serve as the model’s “thinking space.”11 These get optimized during training to carry information that’s hard to express in discrete tokens.
Hybrid: Combinations of the above.
Computation
How is the latent computation actually carried out?
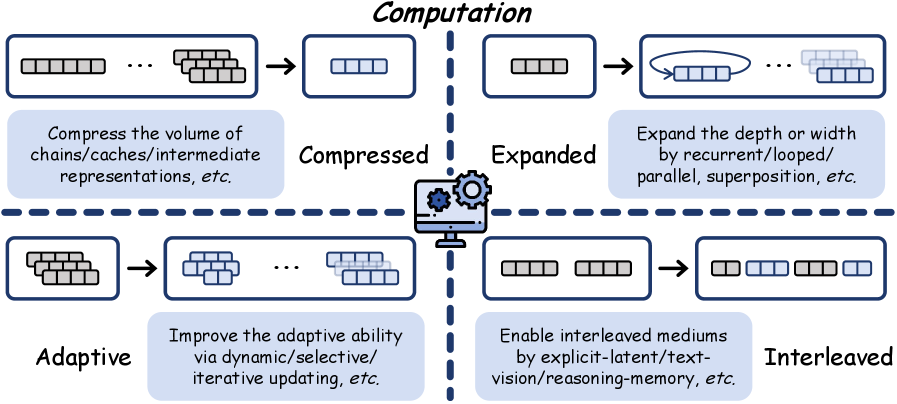
Figure 7: Schematic diagram of the Computation mechanism, including four sub-types: Compressed, Expanded, Adaptive, and Interleaved. Source: Yu et al., 2026.
Compressed: Reducing the number of tokens/steps needed. Instead of a 500-token chain-of-thought, compress the reasoning into 50 latent vectors. This directly saves inference cost.
Expanded: Adding more latent computation to improve quality on hard problems. The latent equivalent of “thinking longer.”
Adaptive: Dynamically deciding how much latent computation to allocate based on problem difficulty. Easy problems get one latent step; hard problems get twenty.
Interleaved: Alternating between latent processing and explicit token generation. Think in latent space for a while, then surface a partial result as text, then dive back in. This preserves some interpretability while still capturing efficiency gains.
Optimization
How do you train models to use latent space effectively?
Pre-training: Training latent reasoning capabilities from scratch.
Post-training: Fine-tuning existing models using latent-space RL, where the reward signal guides the model to use its hidden states more effectively.
Inference-time: Methods that don’t modify the model at all but change how it processes inputs at inference — activation steering, latent search, iterative latent refinement.12
The Seven Abilities
The survey maps latent space onto seven capability areas.
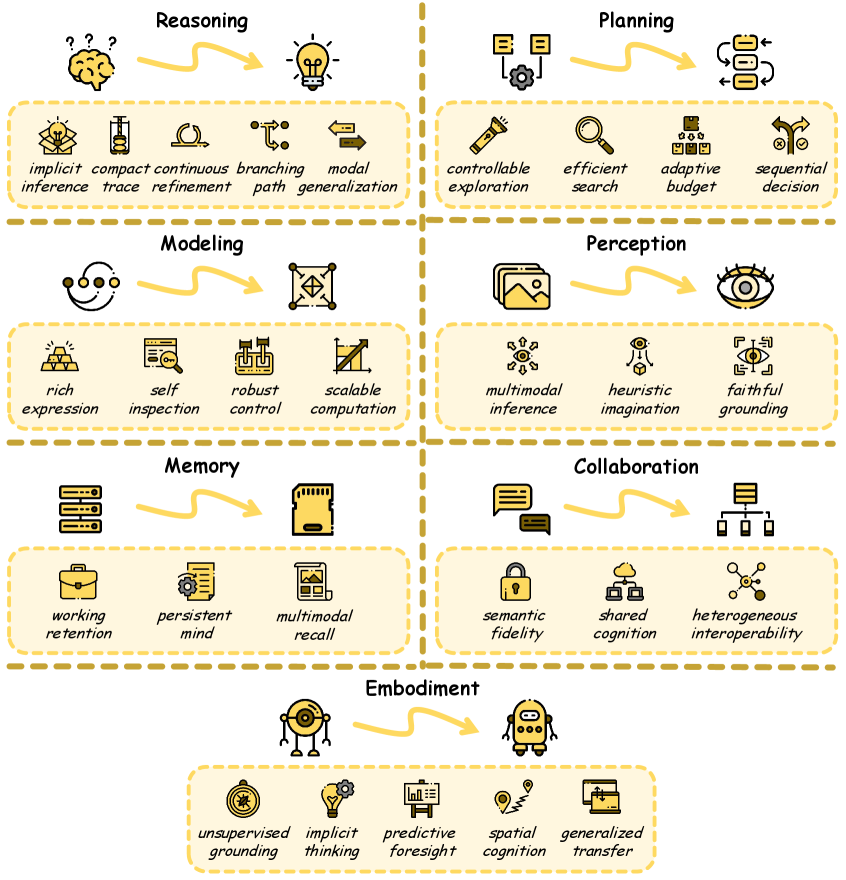
Figure 8: Core abilities brought by the latent space, including: Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Source: Yu et al., 2026.
Reasoning: The original use case. Latent reasoning can match or exceed chain-of-thought performance while using far fewer tokens. Some methods achieve 10–100x compression of reasoning traces.
Planning: Latent space supports search and planning algorithms that would be impossibly expensive in token space. Instead of generating and evaluating plans as text, models can explore a latent plan space continuously.
Modeling: World models — internal simulations of how the world works — are natural latent-space applications. You don’t need to describe the state of a simulated environment in words; you can represent it directly as a latent vector and evolve it forward.
Perception: Vision-language models are increasingly processing visual information in latent space rather than converting it to text descriptions. This preserves spatial information that gets lost in verbalization.
Memory: Long-term memory systems that store and retrieve information as latent vectors rather than text snippets. Higher-bandwidth memory with less storage overhead.
Collaboration: Multi-agent systems where agents communicate in latent space rather than natural language. Instead of two agents exchanging paragraphs of text, they exchange latent vectors that carry the same semantic content in a fraction of the space.
Embodiment: Robots and embodied agents that reason about actions in latent space. Instead of generating text descriptions of what to do, the model outputs latent action representations that map directly to motor control.
Deep Dive: How COCONUT Works
The COCONUT paper (Chain of Continuous Thought, Hao et al., 2024) deserves a closer look because it’s the clearest demonstration of how latent reasoning actually works in practice.
The setup. Start with a standard language model trained with chain-of-thought — it generates step-by-step reasoning as text tokens. COCONUT replaces the discrete reasoning tokens with continuous vectors through a process called “thought token substitution.”
The mechanism. In standard autoregressive generation, the model produces a token, embeds it, and feeds the embedding back as input for the next step. COCONUT modifies this: instead of decoding the hidden state into a discrete token and re-embedding it, it takes the last hidden state directly and uses it as the input for the next reasoning step. The hidden state is a continuous vector in the model’s full representation space — much richer than any single token embedding.
Training. COCONUT uses a curriculum that gradually transitions from explicit chain-of-thought to latent reasoning. It starts with full verbalized reasoning, then progressively replaces more and more reasoning tokens with continuous thought vectors. This lets the model learn to “internalize” reasoning steps that it previously performed explicitly. The training signal comes from the final answer — if the model still gets the right answer after replacing explicit steps with latent ones, the latent representations are capturing the necessary computation.
Key results. On GSM8K (grade-school math), COCONUT matched chain-of-thought performance with significantly fewer reasoning steps. More intriguingly, analysis of the latent representations showed that the model was encoding something resembling breadth-first search — exploring multiple reasoning paths simultaneously in its continuous representations, rather than committing to a single path as sequential token generation forces. This is fundamentally impossible in standard autoregressive generation, where the model must commit to one token (and therefore one reasoning direction) at each step.
Why it matters. COCONUT proved that the vocabulary bottleneck isn’t just an efficiency problem — it’s a capability problem. By removing the constraint that every intermediate thought must be a word, the model gained access to reasoning patterns (like parallel path exploration) that are structurally inaccessible to token-level reasoning.
Deep Dive: The Interpretability-Capability Tradeoff
The tension between capability and interpretability in latent reasoning is not merely a technical inconvenience — it’s a fundamental tradeoff that may define the governance landscape of AI for the next decade.
The capability argument. Latent reasoning is more powerful precisely because it operates in a continuous, high-dimensional space unconstrained by the structure of human language. A 4,096-dimensional vector can encode relationships, uncertainties, and conditional dependencies that would require thousands of words to express — and many that simply cannot be expressed in words at all. Removing the vocabulary bottleneck doesn’t just save compute; it gives the model access to computations that discrete tokens structurally cannot represent.
The interpretability cost. Chain-of-thought reasoning, for all its verbosity, provides a human-readable audit trail. When a medical AI recommends a treatment, clinicians can read the reasoning and catch errors. When a legal AI drafts an argument, lawyers can verify the logic. When a financial model flags a trade, compliance officers can review the rationale. Latent reasoning eliminates this audit trail entirely. The model arrives at an answer through a sequence of continuous vector transformations that no human can inspect, and current interpretability tools can only provide coarse-grained summaries of what happened.
The regulatory dimension. This matters enormously for regulated industries. The EU AI Act requires “meaningful human oversight” for high-risk AI applications. The FDA’s framework for AI in medical devices expects algorithmic transparency. Financial regulators require explainability for automated decisions that affect consumers. A model that reasons in latent space may be more accurate, but it may also be fundamentally incompatible with existing regulatory frameworks — not because the regulations are wrong, but because they assume a degree of inspectability that latent reasoning inherently cannot provide.
The emerging middle ground. The “interleaved” computation approach — alternating between latent processing and explicit token generation — may offer a compromise. The model thinks in latent space for efficiency, but periodically “surfaces” key intermediate conclusions as readable text. This sacrifices some of the efficiency gains but preserves partial interpretability. Whether this middle ground is sufficient for high-stakes applications remains an open and urgent question.
The Elephant in the Room: Interpretability
The survey is admirably honest about the biggest challenge. If models think in latent space instead of words, we lose the ability to inspect their reasoning.13
Chain-of-thought, for all its inefficiency, has one massive advantage: you can read it. You can see when the model makes a logical error, when it gets confused, when it takes a wrong turn. Latent reasoning is opaque by construction. The model reaches the right answer (or the wrong one), and you can’t trace why.
The survey identifies three open challenges:
Evaluability: How do you know if the model’s latent reasoning is correct? You can check the final answer, but you can’t check the intermediate steps. This is fine for math problems with verifiable solutions; it’s terrifying for medical diagnoses or legal reasoning.
Controllability: If the model is reasoning in latent space, how do you steer it? How do you say “think more carefully about X” when the thinking isn’t happening in words? Current steering techniques are crude and unreliable.
Interpretability: Can we develop tools to understand what’s happening inside latent computations? This is an active research area — latent probing, concept discovery in activation space, mechanistic interpretability — but the tools are immature.
The authors frame this as the central tension of the paradigm: the properties that make latent space powerful (continuity, compression, expressiveness) are the same properties that make it difficult to inspect, evaluate, and govern.
Why This Matters Now
First, it’s a roadmap. If you’re building AI systems, the direction of travel is clear. Within the next 1–2 years, the models you use will increasingly do their heavy cognitive lifting in latent space. Chain-of-thought as we know it — the verbose, token-heavy, sequential reasoning — will be compressed or eliminated for efficiency. Products built on the assumption that you can always read the model’s reasoning will need to adapt.
Second, it changes the economics of inference. Latent reasoning is fundamentally cheaper than verbal reasoning. If you can achieve the same quality of thought in 50 latent steps instead of 500 tokens, that’s a 10x reduction in inference cost.14 At scale, this matters enormously. The companies that figure out latent computation first will have a structural cost advantage.
Third, it makes AI genuinely alien. Right now, despite all the hype and fear, AI is still operating in our medium — human language. We can read its thoughts, critique its reasoning, and understand (to some degree) how it reaches conclusions. A system that reasons in latent space is thinking in a representation that has no human-readable equivalent. This isn’t necessarily bad — it might be much more capable — but it does mean the gap between “what the AI is doing” and “what we can understand about what it’s doing” will grow.
Fourth, the multimodal implications are enormous. The survey makes a compelling case that latent space is the natural meeting point for language, vision, and action. Instead of converting everything to text, future multimodal systems will process all modalities in a shared latent space. This should produce better cross-modal reasoning, but it also means the interpretability challenge gets worse — you can’t even fall back on reading the model’s internal monologue because there won’t be one.
The Bottom Line
The thesis of this survey, stripped to its essence: language models are learning to think without language.15
Not because they’re becoming conscious or developing inner lives, but because continuous vector spaces are simply a more efficient medium for computation than discrete token sequences. The same way computers stopped using vacuum tubes and moved to transistors — not because transistors are “better” in some philosophical sense, but because they’re faster, cheaper, and more capable.
The transition won’t be instant. Explicit language will remain the interface — you’ll still talk to your AI in English, and it’ll still answer in English. But the thinking that happens between your question and its answer? That’s increasingly going to happen in a space that no human can directly inspect.
The survey’s closing line is worth quoting: “Latent space holds the potential to become a foundational principle for language-based models.” Not a technique. Not an optimization. A principle. The native language of machine intelligence.
Whether that excites you or terrifies you probably depends on how much you value being able to read your AI’s mind. Because that window is closing.
Paper: “The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook” — Yu, Chen, He, Fu, Yang, Xu, Ma, Hu et al. (35+ authors). NUS / Fudan / Tsinghua / Zhejiang / CUHK / HKUST / and others. arXiv:2604.02029. April 2026.